-
BigQueryML로 유저 세그먼트 클러스터링하기About Data 2023. 10. 27. 08:29
BigQueryML?
구글 빅쿼리 콘솔에서 SQL 쿼리로 간편하게 머신러닝 모델을 만들고, 실행할 수 있는 서비스입니다.
기본적인 회귀 모델부터 K-means 클러스터링, 시계열 분석, DNN, 랜덤 포레스트, XGBoost 등 다양한 모델을 활용할 수 있습니다.
유저 세그먼트?
서비스를 이용하는 고객을 임의의 기준으로 분류한 결과를 의미합니다.
주로 User Persona라고 해서 하나의 모델로 유저를 정의하는 경우도 있지만, 사용자 집단의 동질성이 낮은 경우는 하나의 페르소나보다 각각의 군집으로 유저를 분류하는 것이 유리합니다.
이렇게 유저를 분류하는 것이 중요한 이유는 각 분류마다 원하는 것과 행동 양식이 다르기 때문에 만족도를 느끼는 지점 역시 다르고, 이는 곧 기능 개발과 캠페인 메시지 전달 방향을 설정하는 데도 큰 영향을 끼칠 수 있습니다.
본론
BigQueryML에서 유저 세그먼트를 클러스터링하는 방법은 매우 간단합니다.
유저들의 행동 패턴 몇 가지를 집계한 테이블을 Select하고, 이를 모델로 저장합니다.
예시는 기본 제공 모델인 K-means 클러스터링을 사용했습니다.
CREATE OR REPLACE MODEL `mydataset.mymodel` OPTIONS( MODEL_TYPE='KMEANS', KMEANS_INIT_METHOD='KMEANS++', NUM_CLUSTERS=8 ) AS SELECT -- user_id, feature1, feature2, feature3, feature4 FROM `mydataset.myusertable`쿼리에 대해 하나씩 설명하면, 첫 줄은 생성할 모델에 대한 타겟입니다. 생성된 모델은 여느 테이블처럼 빅쿼리의 데이터셋 안에 저장됩니다.
다음으로 옵션의 MODEL_TYPE에서 실행할 모델을 정하고, KMEANS 모델일 경우 KMEANS_INIT_METHOD 옵션을 추가로 지정할 수 있습니다. 자세한 설명 참고 가능하며, 마지막 NUM_CLUSTERS는 최종적으로 분할할 클러스터의 갯수를 의미합니다.
이 쿼리를 실행한 후 지정한 위치에 생성된 모델을 클릭해보면 '평가' 탭이 있습니다.
여기서는 클러스터의 각 인덱스마다 모델이 학습한 데이터가 어떻게 분포되어 있는지 직관적으로 확인하실 수 있습니다.
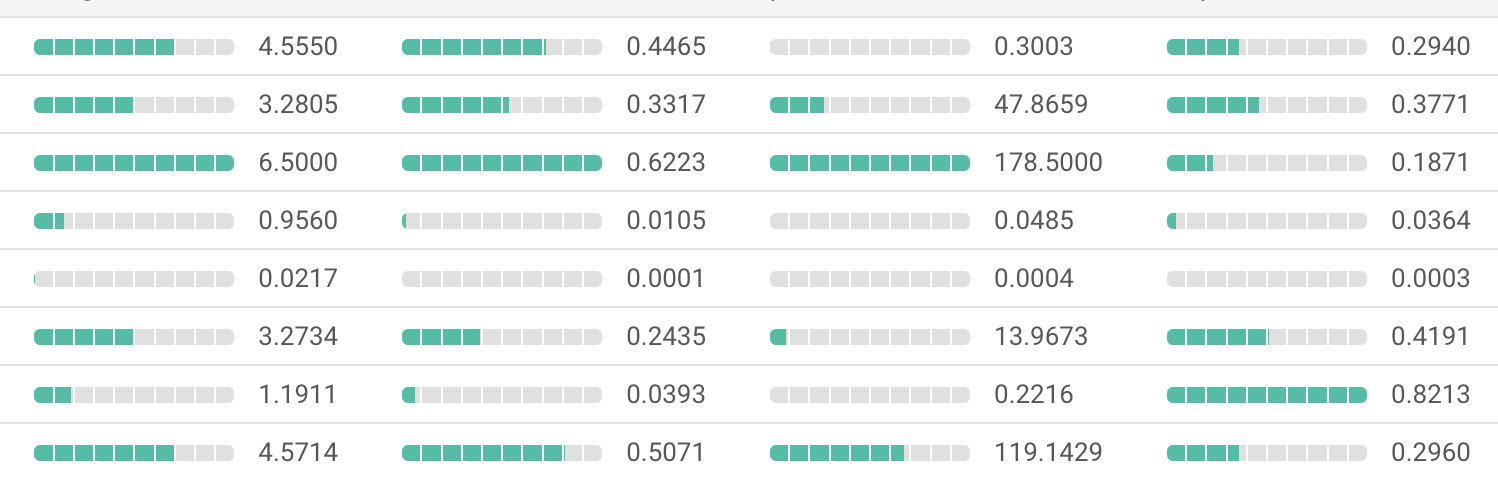
위 그림에 대해 설명하면 왼쪽부터 피쳐 1,2,3,4번이고, 위쪽부터 클러스터 1,2,3,4,5,6,7,8번입니다.
각 셀마다 피쳐들이 어느 정도의 기준 값을 가지고 있는지 나타납니다.
중요한 것은 지금부터입니다.
이렇게 학습된 모델을 바탕으로 앞으로 유저들이 추가되거나 활동 양상이 변할 때 다시 세그멘테이션을 해 주어야 하는데요,
그 방법 역시 간단합니다.
빅쿼리 콘솔에서 아래와 같은 쿼리를 실행합니다.
SELECT centroid_id, user_id FROM ML.PREDICT(MODEL `mydataset.mymodel`, ( SELECT user_id, feature1, feature2, feature3, feature4 FROM `mydataset.myusertable`))이 때 주의해야 할 부분은 모델을 생성할 때는 user_id 필드가 없어야 하고,
모델을 통해 할당할 때는 user_id 필드 + 나머지 피쳐도 동일하게 들어가야 합니다.
실제로 ML.PREDICT 명령어를 실행했을 때 리턴되는 필드는 더 다양하지만, 결과적으로 필요한 것은 어떤 유저가 어느 클러스터에 포함되었는가이기 때문에 최종 결과값에 centroid_id와 user_id 두 가지 필드만을 select했습니다.
빅쿼리 Dataform또는 DBT, Airflow 등 다양한 솔루션을 통해 이 작업을 자동화할 수도 있습니다.
결론
이렇게 매번 업데이트되는 유저 세그먼트를 어떻게 활용하느냐가 중요할 텐데요,
예를 들자면 실험적인 피쳐를 런칭할 때 세그먼트 별로 목표를 설정해서 모니터링할 수도 있고,
직접 실험군 자체를 세그먼트 별로 나눌 수도 있고,
광고 타깃을 뽑을 때 세그먼트를 직접 고려할 수도 있습니다.
물론 이렇게 클러스터링을 할 때 유의할 점도 있습니다.
퀄리티가 낮은 피쳐들을 사용하면 군집이 제대로 형성되지 않거나 군집 내의 동질성이 떨어질 수 있고,
어느 정도는 직관을 이용해 숫자로 이루어진 세그먼트를 살아 숨쉬는 사람의 모습으로 상상할 수 있는 지혜도 필요합니다.
'About Data' 카테고리의 다른 글
Airflow로 마케팅 데이터 파이프라인 관리하기 (0) 2021.07.09 Google Spreadsheet 데이터 DB화 하기 (0) 2021.07.03 Segment -> AWS Glue, S3, Kinesis, Lambda를 이용한 클라이언트 로그 스트림 구축 (0) 2021.07.03 Terraform을 활용한 EMR Presto 도입기 (1) 2021.06.05 사이즈가 큰 csv데이터 S3 -> redshift DB로 Copy하기 (0) 2020.12.18